Supervision Kubernetes avec Grafana et Prometheus
La popularité de Docker n’est plus à démontrer, un rapport récent de Gartner le confirme :

Pour administrer un nombre grandissant de conteneurs, les orchestrateurs sont apparus, ils permettent de gagner en rapidité, en efficacité et en budget, l’infrastructure se met à l’échelle automatiquement en fonction des besoins, intègre des principes de haute disponibilité et de répartition de charge entre autres. De quoi rendre une infrastructure plus résiliente et plus adaptée aux pratiques agiles.
Parmi ces orchestrateurs : Kubernetes, le plus répandu à ce jour, la CNCF (Cloud Native Computing Foundation) annonce « A présent, 84% des entreprises utilisent des conteneurs […]. La grande majorité d’entre elles (78%) utilise Kubernetes pour les gérer ». Pour bien saisir à quel point Kubernetes domine le marché, la CNCF a identifié plus de 109 outils pour gérer les conteneurs, parmi lesquels 89 % utilisent et/ou se basent sur Kubernetes.
L’importance de la conteneurisation et de son orchestration dans le paysage soulève et amplifie des problèmes déjà présents sur les infrastructures plus classiques, parmi elles, la supervision.
Qu’est-ce que la supervision ?
Une définition simple viserait à dire que « La supervision est une technique de pilotage et de suivi informatique de procédés automatisés ».
C’est une méthode de « surveillance » qui vise à s’assurer du bon fonctionnement d’un produit, d’une infrastructure en relevant et agrégeant différentes informations sur lesquelles on pourra se baser pour déterminer l’état de fonctionnement de l’élément que l’on supervise.
Les types de supervisions
La supervision passive va être celle qui va être mise en place en agrégeant les logs, en récupérant les métriques et en les affichant sur un dashboard Grafana, cette supervision sera accessible à qui en aura eu l’accès accordé et pourra être consulté à tout moment, elle sera là principalement comme outil de surveillance et comme aide à la décision.
De l’autre côté la supervision active elle va permettre d’avoir une réactivité accrue, elle se présentera sous la forme d’alertes, configurables sur différents canaux (mail, SMS, messagerie instantanée, etc…) et permettra d’informer d’un état critique (sur des critères définis au préalable) pour permettre une remédiation rapide à une dégradation du fonctionnement d’un produit / d’une infrastructure.
Quels intérêts ?
Quelle est la consommation en ressource de notre infrastructure ? Se porte-t-elle bien ? L’infrastructure est-elle bien dimensionnée ? Bien équilibrée ?
Une supervision bien paramétrée nous permet de répondre à ses questions, de manière passive (par la consultation d’une page web ou d’un rapport par exemple) mais aussi de manière active (par la réception d’une alerte mail ou autre moyen de communication direct et rapide).
Une fois ces informations connues, nous pouvons redimensionner, paramétrer, rééquilibrer l’infrastructure pour qu’elle se porte au mieux tout en ayant un coût au plus proche de nos besoins.
L’intérêt porte donc sur la réaction en cas d’incident ou de mauvais fonctionnement mais aussi sur de l’aide à la décision grâce à des informations clefs sur le fonctionnement du produit que l’on supervise.
Quels outils ?
Les outils de supervisions sont nombreux, Zabbix, PRTG, Datadog, OpManager, Nagios XI, SolarWind Monitor, …
Certains de ces outils sont payants, certains propriétaires, d’autres propres à une technologie ou un outil et ne sont pas toujours interopérables avec d’autres.
Un outil, ou plutôt un binôme gagnant en popularité sur ces dernières années :
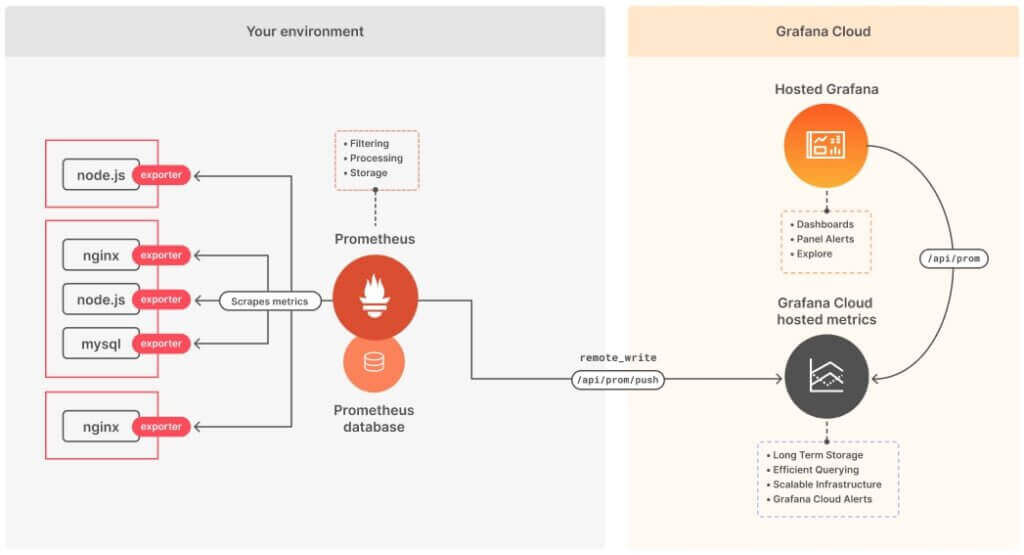
D’un côté Prometheus, une Base de données Temps Série (TSDB) permettant d’enregistrer toutes nos métriques (mesure sur l’état d’un composant, utilisation CPU, nombre de requête, quantité de RAM utilisée, taux d’erreur, …) avec un aspect temporel.
De l’autre Grafana, un agrégateur, visualisateur de données. Il est entièrement configurable, de nombreuses visualisations sont disponibles, de même pour les sources de données (OpenTSDB, InfluxDB, Graphite, Loki, Elasticsearch, Tempo, Jaeger, MySQL, PSQL, etc…) dont Prometheus fait partie.
Ces deux outils sont open source, un atout de taille pour certains clients qui ne souhaitent pas dépendre de solutions propriétaires.
Ce binôme est accompagné d’un agrégateur de log (Graylog par exemple), qui permet de centraliser les logs sur une plateforme unique, et de les mettre en relation rapidement. Nous pouvons donc rapidement filtrer les logs provenant de dizaines de sources différentes et identifier les causes plus précises d’une éventuelle défaillance.
Prometheus fonctionne de pair avec des « exporteurs » qui sont des petites briques logicielles faisant apparaitre les métriques sur une interface web. Une fois ces métriques accessibles depuis une interface web, Prometheus va aller les « scrapper », c’est-à-dire récupérer les données de lui-même pour ensuite les enregistrer dans sa base de données. C’est un fonctionnement de type « pull », contrairement au « push » ou ce sont les logiciels qui envoient les informations d’eux même dans la base de données. Chaque élément devant être supervisé devra intégrer une de ces briques (souvent déjà existantes et soutenues par la communauté) pour pouvoir être prise en charge par Prometheus.
Particularités de Kubernetes
L’une des grosses particularités de Kubernetes et de la conteneurisation en général repose sur la non persistance des containers (briques de calcul), ils peuvent s’arrêter à tout moment (et redémarrer aussitôt si Kubernetes le décide) ce qui rends les logs et autres métriques très volatiles, difficile d’assurer un suivi sur ces données qui peuvent disparaitre d’un moment à l’autre.
L’intérêt de mettre une supervision en place est d’autant plus forte que le nombre de container peut être important. Les données (logs et métriques) seront sauvegardées sur des éléments « externes » ayant pour but de garder ces données.
Les logs seront eux automatiquement redirigés sur la plateforme de log et donc conservés par cette instance particulière ayant un stockage persistant.
Concernant les éléments devant être supervisés via métriques, ils seront automatiquement taggués à la création pour que Prometheus (via un système d’auto-discovery) puisse allez les interroger et enregistrer leurs métriques dans son stockage persistant.
L’aspect volatile de Kubernetes peut aussi poser problèmes en cas de modification d’une ressource, les changements d’état sont rapides, les répercussions immédiates et leur propagation rapide. La supervision active permet d’être aussitôt averti d’un tel comportement indésiré et donc de réduire les dégradations et éventuelles interruptions de service.
Par Anthonin Presse, Expert de notre Digital Factory BAW
Retrouvez une sélection d’articles et de ressources de nos Experts Digital Factory BAW :
- Les Enjeux des Architectures Conteneurisées – Article
- Cloud Hybride : Problématiques et facteurs de succès de la cohabitation d’architectures propriétaires – Article
- « Cloudisation » du Système d’Information – Article
- Stratégie SI à l’ère du Cloud Computing, vous accompagner dans votre stratégie « Cloud au Centre » – Article
- Architecte SI Hybride/Digitale : Un véritable besoin d’accompagnement – Article




